|
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Глава 9 Управление процессами Время — это средство, с помощью которого Природа не дает всему происходить сразу. В компьютерах таким средством служат процессы. Процесс — это исполняющаяся программа. Он состоит из исполняемой программы, данных программы и некоторой информации состояния (определяется ниже), необходимой для ее выполнения. Любая ОС имеет средства поддержки процессов. Ранее мы говорили, что процесс можно считать единицей работы системы. Это положение по-прежнему остается в силе. Вероятно, наиболее четкое интуитивное представление о процессе можно получить, если представить себе систему с разделением времени. Разделение времени, как отмечалось в главе 8, означает одновременное совместное использование процессора и памяти несколькими пользователями. Разделение времени создает у пользователя иллюзию собственного компьютера. Если в компьютере всего один процессор, то в каждый конкретный момент времени программу может исполнять только один пользовательский процесс. Управление процессами — это компонент SLIC, который не дает всему происходить сразу, переключая между процессами ресурсы единственного процессора. Периодически ОС принимает решение прекратить один процесс и начать другой, например, если первый использовал весь выделенный ему интервал времени процессора. Если по этой причине процесс временно приостанавливается, то позднее он будет продолжен, начиная в точности с того места, где прекратился. Следовательно, вся информация о процессе, называемая информацией состояния, должна быть на время приостановки процесса где-то сохранена. Компонент распределения работ OS/400 имеет те же самые функции, но на более высоком уровне. Возможность эффективно распределять работы в системе, важна для производительности широкого класса приложений. Мы начнем с основ управления процессами, а затем обсудим взаимосвязи между управлением процессами и распределением работ. Лучшая в мире структура задач Конкурентоспособность вычислительной системы часто достигается лишь благодаря нескольким базовым идеям. Идеи, принесшие заслуженную славу AS/400 — это независимость от технологии, обеспечиваемая MI, и высокая производительность, поддерживаемая одноуровневой памятью. Но есть столь же важные, хотя намного менее известные находки разработчиков. Одна из них — структура задач AS/400, которая пока еще так широко не обсуждалась. IBM, в соответствии с общепринятыми правилами бизнеса, всегда стремилась запатентовать важные идеологические новшества в своей продукции. Патенты, защищая исключительные права на новые идеи, дают компании-владельцу преимущества перед конкурентами, которые не могут их копировать на законных основаниях. Большую прибыль приносят также продажи прав на использование новых технологий другим компаниям. Поэтому появлению AS/400 на рынке предшествовало исследование, целью которого было выбрать наиболее интересные запатентованные технологические новшества для этой системы. Наиболее важным был Патент США № 4 177 513, защищавший структуру задач System/38 и AS/400[ 75 ]. Структура задач — основа построения ОС AS/400. На ней базируются компонент управления процессами SLIC и компонент распределения работ OS/400. В предшествующих главах при обсуждении большинства разделов ОС мы начинали с самого «верхнего» уровня системы и постепенно спускались «вниз». Теперь же я намерен изменить привычный порядок и начать обсуждение «снизу». Причина — фундаментальная важность для AS/400 структуры задач. Но, прежде всего, хотелось бы сказать несколько слов о будущих направлениях развития операционных систем. Надеюсь, это поможет Вам понять, почему структура задач так важна, Технологии микроядра Микроядро — одна из наиболее горячо обсуждаемых сегодня тем в информатике. Сторонники микроядра утверждают, что эта небольшая центральная часть ОС — основа для модульных, переносимых ОС. Оппоненты же говорят, что микроядро ограничивает возможности многопользовательской ОС. Чуть ли не каждый специалист имеет свою собственную точку зрения на то, как сервисы ОС должны быть распределены относительно микроядра. И все же по одному из положений критики, кажется, договорились — это используемая микроядром схема взаимодействия на основе передачи сообщений. Большинство экспертов считает, что это направление — будущее всех ОС, независимо от того, используют они микроядро или нет. Чтобы лучше понять схему взаимодействия на основе передачи сообщений, рассмотрим кратко, как традиционно осуществлялось взаимодействие в ОС. Отличным примером может служить ОС Unix. И первоначальная версия Unix, и большинство современных ее вариантов используют слоеную архитектуру. Группы функций ОС, такие как файловая подсистема, подсистема управления процессами и подсистема ввода-вывода, разделены в ней на слои. Само по себе подобное деление не так уж необычно: большинство ОС, включая ОС AS/ 400, состоят из слоев ПО. Различия между ОС заключаются в способах обмена информацией и взаимодействия между слоями. В системах Unix каждый слой взаимодействует только со слоями, расположенными непосредственно под и над ним. Преимущество такой структуры, на первый взгляд, очевидно: каждый слой «знает» только непосредственных «соседей» снизу и сверху; запросы и отклики передаются от слоя к слою вверх и вниз, как по лестнице. Именно таким образом приложения и сама ОС взаимодействуют с различными компонентами. Такой подход хорошо работает. Лучшее доказательство тому — число Unix-подобных ОС, доживших до сегодняшних дней. Однако такое решение усложняет введение новых или изменение существующих элементов структуры — мешает монолитность конструкции. Иерархия слоев объединяет систему в единое целое. Нелегко вынуть один слой и заменить его новым, так как интерфейсов между слоями много, и они разные. Так что изменения требуют глубокого знания ОС и массы времени. Кроме того, многие API между слоями не документированы, что ставит под вопрос корректность работы кода после внесения изменений. То есть добавить новые функции или перенести их с одного уровня на другой становится настоящей проблемой. Микроядро заменяет описанную вертикальную иерархию взаимосвязей горизонтальной. Все компоненты ОС выше микроядра взаимодействуют друг с другом напрямую, используя проходящие через микроядро сообщения. Микроядро проверяет сообщения, обеспечивает их передачу от одного компонента к другому, контролирует доступ к аппаратным ресурсам. ОС на основе микроядра имеет очень большие возможности расширения. Такая модульная архитектура дает возможность легко подключать новые компоненты, о которых даже и не думали разработчики ОС. При этом работа остальных частей системы не будет нарушена. Однако все имеет свою цену. В ОС на основе микроядра даже тщательно оптимизированная передача сообщений выполняется не столь быстро, как вызов функции в типичной системе Unix. Но производительность системы все равно может быть выше, если удастся избежать прохода через лишние уровни. Все, что было сказано о характере взаимодействий в архитектуре микроядра, применимо и к AS/400. Структура задач как System/38, так и AS/400 использует сообщения, точно так же, как и микроядро. Сообщения хорошо знакомы пользователям OS/ 400: с их помощью взаимодействуют приложения и компоненты системы, в результате этих взаимодействий осуществляется все распределение работ. Подобно микроядру, структура задач AS/400 реализована на самом нижнем уровне системы. В System/38 и ранних моделях AS/400 управление задачами было реализовано в HLIC, а на RISC-системах AS/400 для достижения оптимальной производительности — в SLIC. В основе SLIC — не микроядро, но аналогичные архитектурные концепции. История микроядра началась в середине 80-х в Университете Карнеги-Меллон с разработки микроядра Mach. Технологию микроядра используют многие ОС, созданные в последние годы, например, Windows NT, но впервые она появилась в System/ 38, а затем — в AS/400. Важно отметить, что микроядро — это гораздо больше, чем просто основанный на передаче сообщений механизм взаимодействия и диспетчеризации. Чтобы лучше это понять, мы начнем изучать управление процессами в AS/400 с нижних уровней системы. Начинаем снизу Ранее мы определили процесс как единицу работы в системе. То же самое можно сказать и о задаче. Но по сравнению с задачей, процесс в SLIC — понятие более высокого уровня, он построен над задачей. Имеется и третья, еще более значимая единица работы в OS/400, называемая заданием. Мы увидим далее, как связаны между собой эти три единицы работы в AS/400. Термины «задача» и «процесс» появились в двух разных проектных группах System/38. Инженеры говорили о задачах, а программисты — о процессах. Многие полагали, что поскольку имена разные, то ими обозначают фундаментально разные понятия, но это не так. В начале разработки System/38 мы пытались определить механизм, с помощью которого ОС смогла бы выполнять свою основную обязанность — распределять работы и ресурсы внутри системы. Мы хотели быть уверены, что все делаем правильно. Тогда, в начале 70-х, идея процесса как единицы работы в системе только-только начала использоваться. Но мы полагали, что она подойдет нашей ОС. Развитие процессоров в течение 60-х годов шло довольно бурно. И все же в те дни процессоры ничего не «знали» о процессах, а «понимали» только прерывания. Прерывание — это изменение нормальной последовательности исполнения команд, вызванное либо ошибкой команды, либо чем-то за пределами исполняющейся программы, обычно вводом-выводом. Процессор запускал операцию ввода-вывода, которая затем выполнялась без его участия. Когда ввод-вывод завершался, нужно было как-то сообщить эту информацию процессору, и в качестве такого механизма использовались прерывания. Прерывание останавливает исполняющуюся программу и передает управление обработчику прерываний, который предпринимает нужные действия. После этого управление возвращается прерванной программе. Обработчик прерываний обязан возобновить исполнение прерванной программы в точности с того же момента, на котором оно было прервано. Это означает возвращение всех внутренних регистров в состояние, предшествовавшее прерыванию. Некоторые процессоры имеют несколько наборов регистров, и при возникновении прерывания обработчик использует другой набор. Возвращение управления прерванной программе подразумевает переключение обратно на старый набор регистров. Большинство схем обработки прерываний используют идею приоритета. Приоритет располагает прерывания в порядке их важности, от наиболее к наименее важным. При возникновении прерывания процессор переключается на другую программу только в том случае, если эта программа приоритетней той, что исполняется в данный момент. Большинство процессоров поддерживают ограниченное число приоритетов прерываний. Для поддержки процессов ПО ОС использует механизм прерываний и надстраивает над ним процессы.
В 70-х годах, работая над новым микропрограммируемым процессором для System/38, мы надеялись, что, построив структуру процессов непосредственно над аппаратурой и устранив некоторые накладные расходы прерываний, сможем достичь высокой эффективности системы. Такая структура процессов могла бы использоваться даже вводом-выводом без отдельного механизма прерываний. Это также сократило бы число схем процессора — цель, близкая и дорогая сердцу каждого разработчика. Фактически, нужно было создать структуру процессов системы и написать для ее поддержки микрокод. Но попытки объяснить кому-либо из инженеров-аппаратчиков, что мы делаем, давали весьма интересные результаты. Я очень хорошо помню одну такую дискуссию с техническим менеджером Реем Клотцем и его подчиненными. Я объяснял, что благодаря новой структуре мы не будем ограничены лишь несколькими уровнями прерываний. Мы сможем поддерживать сотни процессов, каждый из которых будет иметь свой уровень приоритета. При желании, даже каждое устройство ввода-вывода может иметь свой собственный приоритет, так как наша система будет поддерживать множественные процессы. Рэй прервал меня вопросом: Вы хотите сказать, что разрабатываете мультипроцессор? Нет, — ответил я, — мы строим систему для поддержки множественных процессов, а не множественных процессоров. В чем же разница? Процесс — это то же самое, что и задача, — сказал я, а затем повторил, — Мы строим систему для поддержки множественных задач, а не множественных аппаратных процессоров. После краткого молчания Рэй поинтересовался: Но тогда, почему вы не называете их просто задачами? С этого дня мы так и стали их называть. Диспетчеризация задач в AS/400 С каждой задачей AS/400 связан блок управления в памяти, который называется элементом диспетчеризации задач TDE (task dispatching element). TDE — это фундаментальная структура данных, лежащая в основе управления задачами. Структура TDE не видима над MI, так как расположена ниже него. Эта структура не системный объект, но важный компонент некоторых из них. Далее в этой главе мы рассмотрим процесс MI и увидим, каким образом TDE включена в этот системный объект. TDE содержит всю информацию, необходимую для управления выполнением задачи. Задача — это исполняющаяся программа, а TDE отвечает и за программу и за состояние ее выполнения. Состояния задачи
состояние характеризует способность задачи выполняться процессором. Любая задача в системе может находиться в одном из четырех состояний. Обратите внимание, что каждое состояние может обозначаться несколькими терминами. В данном разделе мы используем имена состояний SLIC. Итак, четыре состояния задачи — это: Подвешенность — задача находится в этом состоянии, когда начинается или завершается. Такая задача не может исполняться процессором. Готовность — состояние задачи, которая готова к выполнению, но еще не выполняется. За пределами SLIC данное состояние также иногда называется «не избранным», то есть вместо данной задачи исполняется некоторая другая.
Рисунок 9.1. Состояния задачи Исполнение — состояние задачи, называемое вне SLIC активным. В любой момент времени на одном процессоре может исполняться только одна задача. Ожидание — задача чего-либо ожидает, обычно, завершения ввода-вывода, и при этом не может исполняться. Четыре состояния задачи и возможные переходы между ними показаны на рисунке 9.1. Всего возможно 12 переходов из одного состояния в другое, но в AS/400 разрешены только шесть, а именно: Инициирование задачи (подвешенность — готовность): работа начата, и задача переводится в состояние готовности к исполнению. Запуск задачи (готовность — исполнение): перевод задачи в исполняющееся (активное) состояние. Подвешивание задачи (исполнение —подвешенность): по завершении работы задача переводится в подвешенное состояние. Вытеснение задачи (исполнение — готовность): еще не завершенная задача переводится обратно в готовое состояние. Данный переход предполагает наличие в системе других задач, которые более важны (приоритетны). Ожидание (исполнение — ожидание):некоторая операция, запущенная задачей, например, ввода-вывода, заставляет задачу ожидать своего завершения. Сигнализация (ожидание — готовность): операция, окончания которой ждала задача, завершилась, и задача переходит в состояние готовности (не избранности). Некоторые из этих переходов знакомы тем, кто работал с командой «WRKSYSSTS». Она показывает частоту выполнения следующих переходов: «исполнение — ожидание», «исполнение — готовность» и «ожидание — готовность». Данные значения используются при настройке уровня активности в пуле памяти. (На уровнях активности и пулах памяти мы подробно остановимся далее в этой главе). Текущее состояние задачи определяется местом связанного с ней TDE. TDE перемещаются в системе, но не физически, а логически. Все TDE расположены в памяти AS/400. TDE содержит поля адресов, связывающие его с другими структурами данных. Когда говорят о перемещении TDE, имеют в виду, что адреса в структурах данных изменяются для логического перемещения TDE в другую структуру данных. Операции, выполняемые SLIC для связывания различных адресов памяти — вставка TDE в структуру данных и удаление его оттуда — называются постановкой в очередь и удалением из очереди. Эти операции связывания выполняются очень быстро по сравнению с физическим перемещением TDE. Очередь диспетчеризации задач
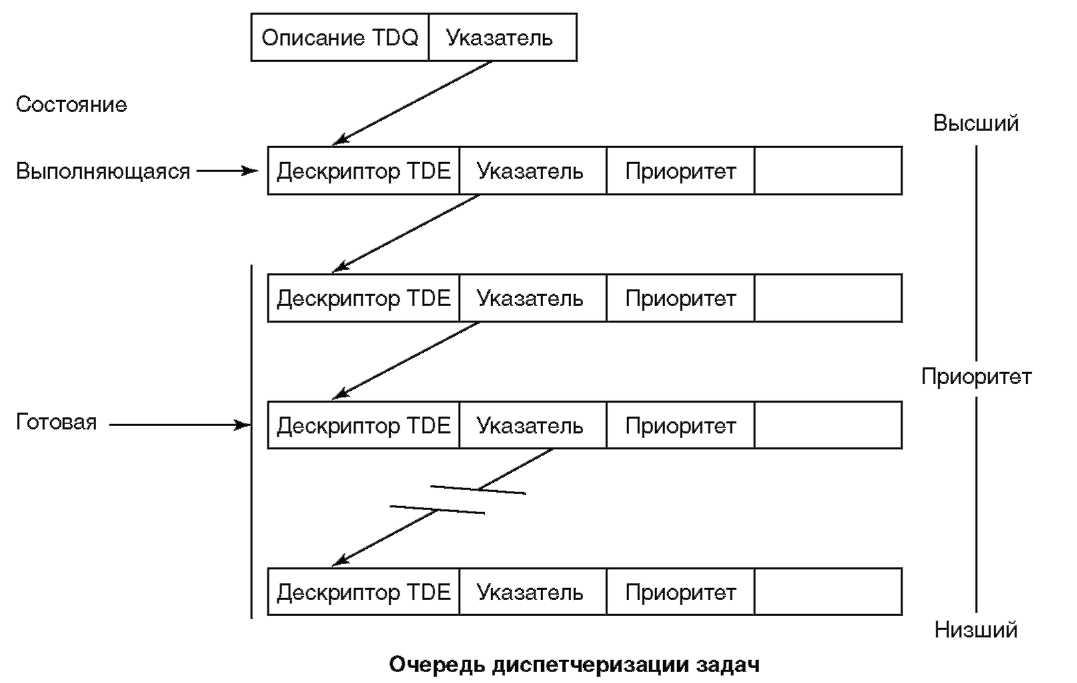
TDE всех задач, которые могут выполняться на процессоре в любой данный момент времени, объединены в структуру данных, называемую очередью диспетчеризации задач TDQ (task dispatching queue). TDQ реализована как связный список в памяти, в котором TDE упорядочены по приоритетам, как показано на рисунке 9.2. Каждый TDE содержит поле приоритета, которое используется для упорядочения. TDE для приоритетной задачи открывает список. Находящийся в SLIC диспетчер задач выбирает приоритетный (первый в списке) TDE и передает ему управление процессором. Таким образом, первый TDE связан с задачей, которая в данный момент исполняется процессором. Все остальные TDE в TDQ связаны с задачами в готовом состоянии. Текущая задача продолжает исполняться до тех пор, пока ей не придется отдать управление процессором. Причин тому может быть несколько. Исполняющаяся задача может запустить операцию, которая заставит ее отдать управление, например ожидание завершения ввода-вывода. Отдать управление также приходится, когда задача полностью использует выделенное ей время процессора. Кроме того, может случиться, что исполняющаяся задача будет вытеснена другой, более важной (приоритетной). Всякий раз, когда исполняющаяся задача отдает управление, оно передается задаче, следующей по важности в TDQ, которая и становится новой исполняющейся задачей. Таким образом, любой TDE в TDQ находится по определению либо в исполняющемся, либо в готовом состоянии.
Рисунок 9.2. Очередь диспетчеризации задач Очереди и счетчики приема-передачи В основе метода синхронизации выполнения задач, а также и для связи между задачами лежит семафор Дейкстры (Dijkstra). В 1968 году Дейкстра предложил примитив для синхронизации исполнения процессов в ОС с мультипрограммированием. Синхронизация — это способность задачи приостанавливаться и ждать до тех пор, пока другая задача не выполнит некоторую операцию. Семафор предоставляет задаче механизм ожидания. Семафор имеет счетчик и список ожидания. Определены две операции (команды). Синхронизация задач осуществляется следующим образом. Оператор V увеличивает значение счетчика на 1. Оператор P проверяет значение счетчика; если оно больше 0, то уменьшает значение на 1 и дает возможность выполняться следующей команде в потоке. Если значение счетчика не больше 0, то оператор Р ждет пока значение увеличится и станет больше 0, прежде чем операция завершится и следующая команда сможет выполняться. То есть ситуация, когда при выполнении оператора Р счетчик не больше 0, означает ожидание. В этом случае, задача, выполнившая оператор Р, ждет до тех пор, пока какая-либо другая задача не увеличит счетчик с помощью оператора V. Во многих случаях, при синхронизации желательно обменяться некоторой информацией или сообщением. Для поддержки синхронизации и передачи сообщений AS/ 400 определяет очередь приема-передачи SRQ (send/receive queue). SRQ — это структура данных в памяти, используемая как «почтовый ящик» для передачи сообщений от одной задачи к другой. Когда исполняющаяся задача выполняет операцию «Отправить сообщение», в очередь SRQ, связанную с некоторой другой задачей, добавляется структура данных, называемая сообщением приема-передачи SRM (send/receive message). SRM содержит сообщение, которое исполняющаяся задача желает передать другой задаче. Когда исполняющаяся задача хочет получить сообщение из SRQ (из своего почтового ящика), она выполняет операцию «Принять сообщение». Если сообщения нет, то задача может подождать его поступления. Если она решает ждать, то TDE исполняющейся задачи извлекается из TDQ и помещается в список ожидания — часть каждой SRQ. Затем вызывается диспетчер задач, который выбирает готовую задачу наибольшей важности и делает ее исполняющейся. Некоторое время спустя другая исполняющаяся задача выполняет для данной SRQ операцию «Отправить сообщение». Если TDE ждет сообщения, то он извлекается из SRQ и помещается в очередь TDQ в порядке важности (приоритетности). Если важность вновь добавленного в очередь TDE выше, чем у исполняющегося, то исполняющая задача вытесняется. Если в процессе ожидания находятся несколько SRQ, то разряд в заголовке SRQ указывает, следует ли при поступлении сообщения «разбудить» их все, или только первую. Любая задача, чей TDE находится в очереди SRQ, по определению находится в состоянии ожидания. На рисунке 9.3 показаны перемещения TDE и то, каким образом положение TDE определяет состояние задачи.
Рисунок 9.3. Перемещения элемента диспетчеризации задач На рисунке не показаны другие структуры данных, которые могут находиться в очередях TDE. Одна из таких структур — счетчик приема-передачи SRC (send/receive counter). SRC не занимается передачей сообщений, так что похож на обычный семафор. SLIC предоставляет операции «Отправить счетчик» и «Принять счетчик», которые позволяют синхронизировать задачи, если обмен сообщениями не нужен. Некоторые читатели, знакомые с командами «SNDPGMMSG» (Send Program Message) и «RCVMSG» (Receive Message) в OS/400 могут спросить: имеют ли эти команды отношение к операциям, используемым структурой задач SLIC. Ответ: «Да, они состоят в очень тесном родстве». Формат SRM, SRQ и SRC спроектирован для управления задачами, но операции добавления и извлечения сообщений из очереди фундаментально одинаковы во всей системе. За реализацию всех этих функций отвечает SLIC. Мультипроцессирование В предшествующем разделе описывались ситуации, подразумевающие наличие только одного процессора, и, следовательно, только одной исполняющейся задачи. На многопроцессорной же системе потенциально может быть несколько исполняющихся задач. Многопроцессорные системы поддерживаются механизмом диспетчеризации задач, большая часть которого присутствовала еще в оригинальной System/38, хотя никогда не использовалась на этой системе. Лишь в 1990 году мультипроцессирова-ние было впервые использовано в AS/400. Оригинальная поддержка мультипроцес-сирования AS/400 до сих пор задействована не полностью, ее резервы предназначены для будущих расширений. Симметричное мультипроцессирование Ранее мы видели, что система симметричного мультипроцессирования (SMP) дает возможность ОС обрабатывать задачи на любом свободном процессоре или на всех процессорах сразу, при этом память остается общей для всех процессоров. Именно так устроена n-канальная (n-way) обработка на AS/400. Любой компонент ОС, включая диспетчер задач, может выполняться на любом или на всех процессорах системы. Диспетчер задач в n-канальной системе автоматически обеспечивает баланс нагрузки между процессорами, не требуя изменения программ, написанных для однопроцессорной архитектуры. Так как память для всех процессоров общая, диспетчер задач, независимо от процессора, на котором он выполняется, имеет доступ ко всем очередям, включая TDQ. Однако, диспетчер задач не ограничен тем процессором, на котором он выполняется, — он может вызвать переключение задач и на другом процессоре. В многопроцессорной системе одновременно исполняется несколько задач — по одной на процессор. Упрощенно, следует лишь направить на выполнение верхние n TDE из TDQ. Естественно, эти n задач имеют наивысшую приоритетность среди всех готовых задач. Однако такой простой метод часто только кажется наилучшим. Предположим, что у нас есть две задачи, А и В, исполняющиеся на процессорах 1 и 2 в двухпроцессорной системе. Предположим далее, что задача С, приоритет которой выше чем у А, но ниже чем у В, выходит из состояния ожидания. Ее TDE будет добавлен в очередь TDQ непосредственно перед TDE задачи А. Диспетчер задач выполнит переключение задач на процессоре 1, чтобы начать исполнение задачи С. Теперь допустим, что задача В на процессоре 2 либо завершилась, либо перешла в состояние ожидания. Приоритет задачи А — наивысший среди готовых задач, и ее следует направить на процессор 2. Но этот выбор может быть не лучшим. В зависимости от того, насколько давно задача А была вытеснена, мы можем захотеть, а можем и не захотеть начать ее выполнение на процессоре 2. Если задача вытеснена недавно, то в кэше процессора 1 по-прежнему находятся команды и данные задачи А. Направление задачи на процессор 2 означало бы, что кэш процессора 2 должен быть перезагружен в результате промахов, что снизит производительность, как данной задачи, так и системы. В данном случае, лучшим выходом было бы начать выполнение на процессоре 2 какой-либо следующей задачи и подождать, пока для задачи А освободится процессор 1. Мы только что описали понятие сродства кэша (cache affinity). Говорят, что данная задача имеет сродство с некоторым процессором на основании содержимого его кэша. Диспетчеризация задач на многопроцессорной версии AS/400 использует комбинацию приоритета, сродства кэша и еще одной характеристики, под названием приемлемость (eligibility). Приемлемость используют, чтобы ограничить возможный набор процессоров для исполнения данной задачи. Приемлемость никогда не изменяется диспетчером задач. Если все процессоры, для которых приемлемо исполнение данной задачи, заняты задачами более высокого приоритета, то данная задача не направляется на выполнение. Итак, задача отправляется на выполнение только в том случае, если доступен процессор, для которого она имеет сродство кэша. Исключение из этого правила делается тогда, когда его соблюдение может привести к простою процессора или если пропускается значительное число задач высокого приоритета в TDQ. Пороговое значение пропуска зависит от числа процессоров и устанавливается SLIC для конкретной системы. Если число пропущенных задач достигает порогового значения, то сродство игнорируется и задача направляет на любой процессор, для которого она приемлема. Если в процессе пропуска задач был достигнут конец TDQ, прежде чем каждому процессору назначена какая-либо задача, то порог пропуска динамически снижается до тех пор, пока не останется либо незанятых процессоров, либо пропущенных задач. Для диспетчеризации задачи на мультипроцессорной системе используются три поля TDE, а именно: Поле приемлемости, где содержится по одному биту на каждый процессор в системе. Если бит установлен, то задача приемлема для выполнения на соответствующем процессоре. Если установлены все биты, то задача приемлема для выполнения на всех процессорах. Поле активности, включающее по одному биту на каждый процессор в системе и указывающее процессор, на котором данная задача в настоящий момент активна. Может быть установлен максимум один бит, если задача выполняется. В противном случае, все биты сброшены. Поле сродства содержит по одному биту на каждый процессор в системе и указывает процессор, на котором данная задача исполнялась в последний раз. Помимо только что описанной поддержки многопроцессорных систем, AS/400 может иметь множественные TDQ. Данный механизм был включен в оригинальную System/38, чтобы обеспечить диспетчеризацию нескольких очередей, но не использовался там для этой цели. Если число процессоров возрастет настолько, что одиночная TDQ станет тормозить работу системы, то диспетчеризацию можно будет осуществлять с помощью нескольких TDQ. Современные n-канальные процессоры используют модель SMP с разделяемой памятью, в которой все процессоры работают с одной и той же памятью. В главе 12 мы рассмотрим другие модели SMP, которые найдут применение в будущих системах AS/ 400. Все они поддерживаются существующей структурой задач. Асимметричное мультипроцессирование Давайте, хотя бы кратко, затронем системы асимметричного мультипроцессирова-ния (ASMP). В системе ASMP части одной или даже разных ОС выполняются на выделенных процессорах. Структура задач AS/400 поддерживает и такую модель мультипроцессирования. Один из ранних проектов System/38 предусматривал несколько процессоров, каждый из которых выполнял часть ОС ниже MI. Идея состояла в том, чтобы выделить один процессор для СУБД, другой для управления памятью и т. д. В данном проекте ASMP использовалась та же структура задач для обмена сообщениями между процессорами и распределения работ. В точности такая модель мультипроцессирования никогда не использовалась в System/38. Однако в AS/400 была введена некая разновидность модели ASMP. В главе 10 мы рассмотрим структуру ввода-вывода AS/400, которая существенно изменилась по сравнению с System/38. AS/400 использует множество процессоров для исполнения разных функций ввода-вывода. Большая система может иметь сотни таких процессоров. Мы увидим, что каждый из этих процессоров имеет собственную ОС. Хотя большинство из таких ОС разработаны специально для поддержки функций ввода-вывода, некоторые из них все же более универсальны. Такая архитектура позволяет другим ОС и написанным для них приложениям исполняться «под крышей» AS/400. Таким образом, к AS/400 возможно подключать множество таких машин-приложений в дополнение к основным процессорам. Динамическое планирование приоритетов В предыдущих разделах мы рассмотрели более понятную, но упрощенную модель диспетчеризации задач в AS/400. Со времен первой System/38 в структуру задач было внесено множество изменений для удовлетворения требований различных приложений и структур системы. Например, мы предполагали, что когда-нибудь системе понадобится динамически настраивать приоритет задачи во время исполнения. Предположим, что задача не получает достаточного для ее решения процессорного времени, или заблокировала некоторый системный ресурс, которого ожидает задача с большим приоритетом. Если бы система могла временно повышать и понижать приоритеты подобных задач, то можно было бы найти выход из только что описанных ситуаций. Такая возможность была добавлена в System/38 и ранние AS/400. С появлением многопроцессорных конфигураций, и особенно в связи с нашим намерением использовать большее количество процессоров в конфигурациях SMP, было решено, что нужна более гибкая настройка приоритета задач. Группа исследователей в подразделении IBM Research в Нью-Йорке работала над механизмом, который они назвали планировщик с оценкой задержки (delay-cost scheduler). Специалисты из Рочестера подключились к этому проекту и вместе с IBM Research создали версию этого планировщика, которая теперь используется в SLIC на всех RISC-системах AS/400. Применяемые в планировщике алгоритмы, пожалуй, слишком сложны для этой книги. Но они вполне позволяют выполнять задачи вне порядка их приоритетов, если производительность системы при этом возрастает. В результате, загрузка RISC-процессоров становится более эффективной, особенно, в n-канальных конфигурациях. Теперь, когда мы закончили рассмотрение самого низкого уровня диспетчеризации задач AS/400, можно перейти к рассмотрению этой функции на более высоких уровнях. Процессы в MI Процесс в MI — это системный объект, называемый пространством управления процессом. Обратите внимание, что эквивалентного объекта OS/400 нет. (Мы еще поговорим об этом в разделах, посвященных управлению работами). Задача процесса в MI — связать воедино ресурсы, необходимые для исполнения, или, точнее, вызова программы. Программы разделяемы, поэтому одна программа может исполняться несколькими пользователями. Конечно, данные, используемые программой, для всех пользователей будут разными. Так как программе необходимо некоторое место для временного хранения используемых переменных, то для каждого ее вызова нужно выделить рабочую область. Ответственность за это лежит на процессе MI. Прежде чем займемся собственно структурой процесса, необходимо разобраться с типами памяти, задействованными исполняющейся программой. На исполнение программы сильно влияют компилятор и ЯВУ. Особенно важно то, как компилятор размещает и адресует переменные, используемые в программе. Часто ЯВУ имеет некоторую форму оператора объявления, позволяющего задать тип переменной и место, где компилятор должен ее разместить. Чтобы понять, какие варианты размещения переменных должен поддерживать процесс, необходимо рассмотреть три отдельные области, используемые для размещения данных современными ЯВУ, а именно: Статическая область памяти. Данный тип памяти компилятор использует для размещения глобальных переменных и констант программы. Переменные называются глобальными, так как эта область памяти доступна любой части программы (на некоторых системах сама область называется областью глобальных данных). Автоматический стек. Эта область памяти используется для размещения локальных переменных. При выполнении в программе процедуры вызова, переменные должны быть где-то сохранены, чтобы их можно было восстановить после возврата. Переменные называются локальными, так как имеют смысл только в процедуре, исполняющей вызов. Вызовы могут быть вложенными, то есть одна процедура может вызвать другую, та — третью и т. д. Соответственно, область для сохранения переменных должна автоматически расти и сокращаться при вызовах и возвратах. В качестве такой области автоматического хранилища используется стек. Стек состоит из двух компонентов: непрерывного блока памяти, содержащей данные, и указателя стека, определяющего положение вершины стека в памяти. Дно стека располагается по фиксированному адресу. При вызове программы адрес указателя стека увеличивается, чтобы предоставить достаточно места для локальных переменных; а при выполнении возврата — уменьшается на соответствующую величину. Таким образом, размер стека растет и сокращается динамически. В некоторых системах эту память называют динамической. 3.Область кучи. Эта область памяти используется для размещения динамичес- ких данных, которые не вписываются в структуру стека. Стек удобен для хранения одиночных переменных (скаляров), так как все его элементы, обычно, одинаковы и равны размеру регистров. Стек не очень хорошо подходит для данных переменной длины, таких как массивы элементов данных. Массивы данных можно хранить в куче. Доступ к массиву в куче осуществляется по адресу, указывающему на его начало, к которому прибавляются смещения элементов. Обратите внимание, что описанные выше области — это области памяти (в общем смысле), а не оперативной памяти. Конкретная система может для реализации этих областей использовать любую комбинацию регистров, оперативной памяти и дисков, поэтому мы и говорим о «просто памяти». Исходная модель процессов
Подобно исходной модели программ (ОРМ), обсуждавшейся в главе 4, исходная модель процессов была разработана для поддержки таких языков, как RPG, Cobol и CL. Исходная модель соответствует структуре, в которой каждый процесс — единица работы. Программы, исполнявшиеся процессами, зачастую не были модульными. Процесс реализован как системный объект в MI. В дополнение к управляющей информации, данный объект либо содержит области памяти, используемые процессом, либо указывает на них. Три описанные выше области памяти, необходимые для процесса, поддерживались в исходной модели процессов следующим образом: 1. Область статической памяти программы PSSA (Program Static Storage Area) — единственная копия статической области памяти для всего процесса. Область автоматической памяти программы PASA (Program Automatic Storage Area) содержала стек вызовов. Область кучи — в исходной модели процессов не поддерживалась. Куча должна была обеспечиваться компилятором каждого языка отдельно. Системный объект MI для процесса исходной модели, который также называется пространством управления процессом, содержит два сегмента: базовый сегмент, где находится основная часть управляющей информации вместе с TDE процесса; а также сегмент рабочей области вызова IWA (invocation work area). Основное назначение последнего — хранение стека вызовов-возвратов процесса. Исходная модель процессов очень хорошо работала для приложений, написанных для System/38 и ранних моделей AS/400. Однако переход на блочно-структурирован-ные языки и необходимость поддержки приложений, написанных в соответствии со стандартами POSIX, привели к разработке модели процессов ILE. Модель процессов ILE
Модель процессов ILE впервые появилась на AS/400 в версии V2R3 вместе с одноименной программной моделью и компиляторами. Исходная модель процессов и модель процессов ILE сосуществовали в AS/400 до перехода на RISC-процессоры. Затем исходные модели были устранены, ведь RISC-системы поддерживают только модель программ и модель процессов ILE. (Модели ILE для программ и процессов создавались специально в расчете на RISC-процессоры.) Давайте рассмотрим модель процессов ILE более подробно. Но прежде остановимся на изменениях, внесенных в AS/400 для поддержки программной модели ILE. В MI для этого используются активизации программ, группы активизации, вызовы процедур и новый процедурный указатель. В главе 4 мы говорили о компиляторах и программной модели ILE. Мы рассмотрели, как ILE изменила способ создания программ, а также концепцию модуля. Вспомним, что модуль — это результат работы компилятора ILE. Модуль содержит одну или несколько процедур. Средство связывания (binder) ILE упаковывает модули в программы и служебные программы. Таким образом, программы и служебные программы могут содержать один или несколько модулей, которые, в свою очередь, состоят из одной или нескольких процедур. Для обращения к программам и процедурам внутри модулей как часть ILE были введены два типа команд вызова («CALLPGM» и «CALLBP»). Программа — это системный объект MI, который всегда вызывается с помощью команды: внешнего вызова «CALLPGM» MI. Аналогично старой команде «CALLX», команда «CALLPGM» для идентификации программы использует системный указатель. Затем эта команда активизирует программу. В ходе активизации завершается межпрограммное связывание: например, если программа использует модули, связанные через ссылку, то происходит разрешение связей со служебной программой. Активизация программы неявно создает группу активизации, которая предоставляет рабочую область для программы, а также инициализирует ее статическую память. Программа состоит из одной или нескольких процедур. Одна из процедур определяется при создании программы как точка входа, и именно ей командой «CALLPGM» передается управление. Операция передачи управления процедуре называется вызовом процедуры. Для вызова всех остальных процедур программы применяется команда «CALLBP». Для идентификации вызываемой процедуры в этой команде используется процедурный указатель. Вызываемая процедура может находиться либо в самой программе (если связана через копию), либо в служебной программе (если связана через ссыл ку). Обратите внимание, что MI контролирует последовательность вызовов на уровне процедур, а не программ. Когда приложение впервые переносится на RISC-процессор, программа исходной модели конвертируется в программу ILE, состоящую из одной процедуры. Таким образом, преобразованная программа исходной модели, как и любая программа с единственной процедурой, всегда вызывается с помощью «CALLPGM». Если программа, созданная компилятором ILE, состоит из нескольких процедур, то первая процедура вызывается с помощью «CALLPGM», а последующие — с помощью «CALLBP». В главе 4 мы также затронули группы активизации. Они предоставляют рабочие области для активизации одной или нескольких программ. Каждая группа активизации имеет собственную область статической памяти, область стека и область кучи. Так как с появлением RISC-процессоров осталась только модель ILE, данная рабочая область поддерживает также все процессы оригинальной модели и заменяет собой старые области памяти PASA/PSSA. Группа активизации — это не системный объект, а часть объекта-процесса MI. Каждый объект-процесс содержит две или более групп активизации, одна из которых используется системой. Каждый процесс содержит также, по крайней мере, одну пользовательскую группу активизации. При переносе процесса исходной модели, созданного на системе с процессором IMPI, на систему с RISC-процессором, этот процесс трансформируется в процесс ILE с одной пользовательской группой активизации. Группа активизации служит не только для разделения на части памяти, используемой процессом. У каждой группы активизации — собственная управляющая информация, что позволяет поддерживать разные режимы защиты, использования файлов и управления транзакциями. Это обеспечивает заданиям поверх MI большую гибкость. Все группы активизации поименованы либо явно пользователем, либо неявно системой. В определении объекта-программы для обычных и служебных программ может быть явно задано, в какой поименованной группе активизации они должны выполняться, что вызывает неявное создание данной группы при вызове объекта-программы. Внутри процесса ILE В этом разделе мы заглянем внутрь процесса ILE. Структура процесса ILE сложна, и, подобно многим другим затронутым нами темам, ее описание насыщено таким количеством имен, сокращений и терминов, что может загнать в угол любого специалиста по компьютерам. И хотя знакомство с ней не обязательно для понимания работы процессов AS/400, я включил этот раздел в книгу ради полноты изложения. Итак, мазохисты, если Вам нужна еще одна порция аббревиатур, читайте. Структура процессов ILE
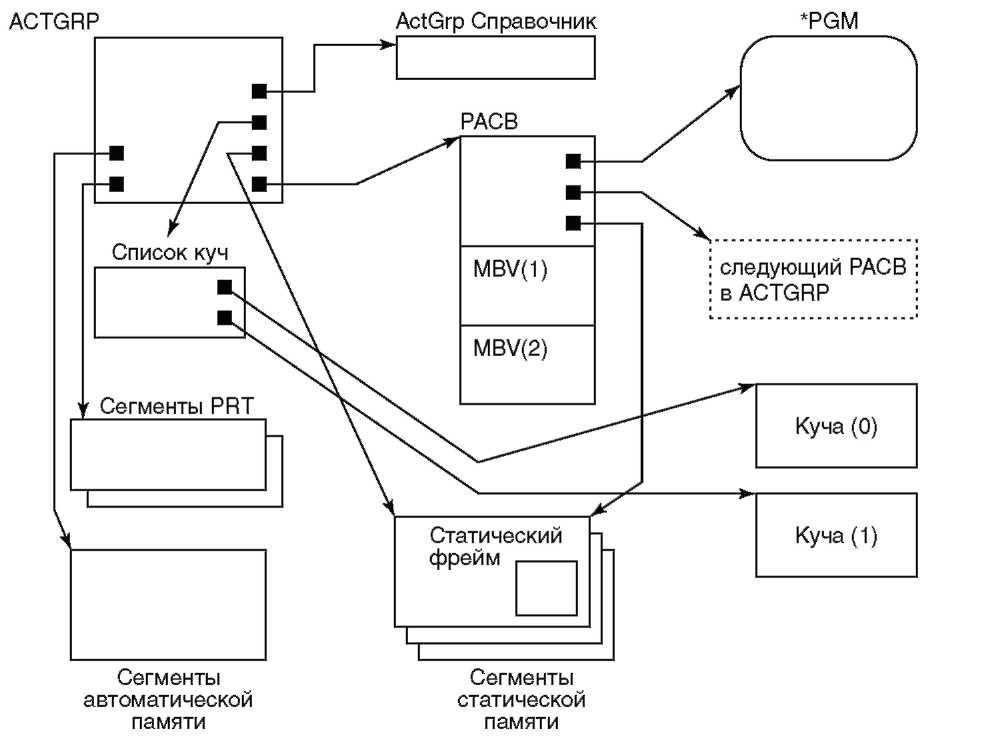
Сначала разберемся с компонентами процесса ILE и сокращениями, их обозначающими: Блок управления процессом PCB (Process Control Block) содержится в системном объекте MI. Ранее мы говорили, что этот системный объект, кроме всего прочего, содержит TDE процесса. Далее мы увидим, что PCB также содержит адреса других связанных с процессом компонентов. Рабочая область активизации процесса PAWA (Process Activation Work Area) представляет собой кучу, используемую для размещения структур времени выполнения, таких как группы активизации. У каждого процесса — одна PAWA. Родительская группа активизации PAGP (Parent Activation Group) — это корневая структура подструктуры процесса, содержащая список всех групп активизации процесса. Несмотря на свое название, сама PAGP не является группой активизации. Группа активизации ACTGRP (Activation Group) предоставляет активизации программы ресурсы памяти (стек, статическую память и кучу). ACTGRP похожа на минипроцесс. Могильные сегменты (Tombstone Segments) используются для создания указателей объектов процесса POP (process object pointer) — описателей (handle) структур SLIC. Описатели используются многими ОС, включая OS/ 2 и Apple Macintosh как косвенные указатели блоков памяти в куче. Вместо прямой адресации таких блоков описатель ссылается а основной указатель, обычно расположенный по фиксированному адресу и содержащий адрес блока. При перемещении блоков по памяти нужно изменять только значение основного указателя. Сегменты называются могильными, так как они предотвращают непосредственный доступ к структурам SLIC; даже если уровень защиты системы разрешает доступ к этим сегментам. Основной указатель находится в области памяти, доступной только SLIC. Область очередей процесса (Process Queue Space) — в ней размещаются одна или несколько очередей приема-передачи (SRQ) сообщений. На рисунке 9.4 показано расположение перечисленных компонентов в структуре процессов ILE. Обратите внимание, что в PAWA содержится список всех групп активизации (PAGP) и сами эти группы. На рисунке показаны четыре группы активизации, хотя как уже упоминалось, их может быть минимум две. По умолчанию всегда первая ACTGRP — это системная группа активизации, а вторая — пользовательская группа активизации.
PCB = Блок управления процессом PAWA = Рабочая область активизации процесса PAGP = Родительская группа активизации ACTGRP = Группа активизации Рисунок 9.4. Структура процесса ILE А теперь заглянем внутрь группы активизации. Группа активизации ILE Группа активизации содержит целиком или только ссылки на некоторые компоненты со странными, на первый взгляд, именами и аббревиатурами. Давайте сначала разберемся, что это за компоненты. Блок управления активизацией программы PACB (Program Activation Control Block) используется в процессе выполнения программы для хранения адресов. Эта структура позволяет находить процедуры и данные, связанные с программой. Для каждой активной программы имеется по одному PACB, и каждый PACB содержит один или несколько векторов связывания модулей. Вектор связывания модулей MBV (Module Binding Vector) предназначен для хранения адресов, используемых модулем. Он содержит адреса данных и процедур, на которые ссылается модуль. Справочник группы активизации (Activation Group Directory) представляет собой каталог имен, используемый для позднего связывания программ и данных. Справочная таблица процедур PRT (Procedure Reference Table) — одна на каждую группу активизации. Ее сегменты содержат точки входа процедур, используемые для вызовов между группами активизации и через процедурные указатели. Список кучи (Heap List) идентифицирует области кучи, связанные с данной группой активизации. Область кучи (Heap Spaces) состоит из управляющего сегмента и нескольких сегментов данных. Управление кучами для MI и SLIC осуществляется диспетчером кучи SLIC. Сегменты автоматической памяти (Auto Storage Segments) содержат стек, используемый группой активизации для автоматической памяти. Сегменты статической памяти (Static Storage Segments) — место, где располагается статическая память группы активизации. На рисунке 9.5 показано расположение перечисленных компонентов в группе активизации.
PACB = Блок управления активизацией программы MBV = Вектор связывания модулей PRT = Справочная таблица процедур Рисунок 9.5. Группа активизации ILE Итак, подведем итоги. Каждый процесс AS/400 содержит PAWA. Внутри PAWA находятся PAGP, а также две или более ACTGRP. В каждой ACTGRP — PACB, содержащий несколько MBV, каталог группы активизации, PRT, список кучи, одну или несколько областей кучи, сегменты автоматической и статической памяти. Надеюсь, теперь Вам все понятно? Исключения, события и прерывания Если нечто не соответствует общему правилу, то его обычно называют исключением из правила. В вычислительных системах также имеются исключения из общих правил обработки. В этом разделе мы рассмотрим обработку исключений, событий и прерываний на AS/400. На аппаратном уровне обычно говорят о прерываниях. Как упоминалось выше в этой главе, прерывание — это событие, отличное от команды перехода, которое изменяет нормальный порядок выполнения команд. Причиной прерывания может быть выполнение некоторой команды или некоторое действие за пределами текущей программы, например, завершение операции ввода-вывода. Архитектура PowerPC определяет полноценный механизм прерываний, позволяющий процессору изменять свое состояние в ответ на внешние сигналы, ошибки и необычные ситуации, возникающие при исполнении команд. Мы еще рассмотрим это подробнее. Программы и процессы MI ничего не «знают» о прерываниях на аппаратном уровне. Однако, о прерывании, возникшем в результате исполнения программы MI, должно быть сообщено MI. За обнаружение, обработку и сообщение MI о прерываниях отвечает SLIC. Исключения и события MI В MI различаются исключения и события. Исключение — это либо ошибка, обнаруженная машиной при исполнении команды, либо определенное состояние, обнаруженное пользовательской программой. Событие — это происшествие, возникающее в процессе работы машины и, напротив, представляющее интерес для ее пользователей. Исключения синхронны, то есть вызываются исполнением некоторой команды. События асинхронны, то есть их причина — за пределами исполняющейся в данной момент команды. Часто исключения и события очень легко перепутать. Рассмотрим несколько примеров. Предположим, что программа пытается разделить число на 0 — очевидная ошибка. Когда эта ошибка обнаружится, о ней будет сообщено с помощью исключения. Исключение синхронно, так как, если данные всегда одинаковы, та же самая ошибка будет происходить в том же самом месте при каждом выполнении программы. Теперь представим себе, что параллельно с программой исполняется операция ввода-вывода, например, чтение записи с диска. В некоторый момент времени операция ввода-вывода завершается, и об этом факте необходимо сообщить. Механизм сообщения о завершении ввода-вывода — это событие, так как его причина — действие, не связанное с выполняемой в данный момент командой. Оно асинхронно, то есть оно не связано с исполнением программы и может произойти в любой момент. Подобно подразделению исключений MI на два типа: ошибки и пользовательские состояния, — есть и два типа событий. Это объектные события, например, исчерпание максимума сообщений в очереди, и машинные события, например, истечение заданного интервала времени. Процесс MI следит за наступлением событий из определенного набора, и когда происходят все или некоторые из них, выполняет нужные действия. С появлением моделей программ и процессов ILE в модель исключений были внесены изменения. Исключение в MI — формально определенное сообщение процесса. Все сообщения процесса хранятся в пространстве очередей процесса, являющемся частью структуры процессов ILE, описанной в предыдущем разделе. Так как исключение доставляется как сообщение, то возможна задержка между сигнализацией об исключении и его обработкой. Эти характеристики описанной структуры исключений одинаковы и для исходных моделей, и для моделей ILE. С появлением ILE мониторинг и обработка исключений стали явно управляться пользователем MI. Мониторы исключений используются для отслеживания исключений. Существуют команды MI для включения и отключения мониторов исключений. Одновременно может быть включено несколько мониторов. У каждого из них свой приоритет, в соответствии с которым осуществляется поиск и обработка прерываний в том случае, если включено несколько мониторов. С каждым монитором всегда связана внешняя процедура ILE, обрабатывающая исключения. SLIC поддерживает мониторинг и обработку как событий, так и исключений. В главе 5 мы говорили, что машина ведет мониторинг доступа к системным объектам. Если добавить к этому некоторые специальные команды PowerPC, то получится почти полное представление о масштабах этой функции. Контроль за исключениями осуществляется, в основном, аппаратурой, которая сообщает о них процедурам обработки исключений SLIC с помощью механизма прерываний PowerPC. В следующем разделе мы рассмотрим компонент управления исключениями SLIC. Управление исключениями SLIC
Управление исключениями в SLIC заключается, в основном, в маршрутизации. Маршрутизация запускается механизмом прерываний PowerPC, когда аппаратура обнаруживает прерывание. После возникновения исключения все соответствующие компоненты SLIC получают возможность обработать его. Если исключение обработано, то процесс продолжается, как будто ничего не произошло. Если же исключение не обработано SLIC, то процесс завершается и исключение передается соответствующему обработчику исключений ILE. Прерывания классифицируются по тому, вызваны ли они исполнением конкретной команды или каким-то другим событием в системе. В архитектуре PowerPC определено 15 типов прерываний. Пять прерываний генерируются аппаратно, а именно: сброс системы (System Reset) — прерывание при выключении или включении системы; машинная ошибка (Machine Check), служащая для сообщения об аппаратных сбоях; внешнее (External) — прерывание, уведомляющее процессор о том, что некоторое событие за его пределами (например, ввод-вывод) требует внимания; монитор производительности (Performance Monitor), при включенном мониторинге производительности уведомляющий процессор о событии, за которым ведется наблюдение; уменьшитель (Decrementer), используемый таймерами и извещающий процессор об истечении некоторого интервала времени. Некоторые прерывания генерируются в результате выполнения команд. Перечислим их. Память данных (Data Storage) — это прерывание сообщает, что команда предприняла безуспешные попытки доступа к хранилищу данных. Используется для сигнализации о невозможности трансляции эффективного адреса (страничная ошибка), нарушении защиты памяти или переполнении эффективного адреса (ЕАО). Память команд (Instruction Storage) аналогично прерыванию памяти данных, но вызывается попыткой выбрать команду для исполнения. Ошибка прямого сохранения (Direct-Store Error) также аналогично прерыванию памяти данных, но возникает при обращении по адресу прямого сохранения (DS). Отметьте, что по этому адресу не может произойти страничная ошибка. Выравнивание (Alignment) происходит при попытке обращения к операнду, который не выровнен на необходимую границу памяти. Программное (Program) прерывание используется для сообщений типа попытки процессора выполнить привилегированную команду при отсутствии у пользователя соответствующих прав или попытки применить неверный код операции. «Нет плавающей точки» (Floating-Point Unavailable) — прерывание с этим названием возникает при попытке выполнить команду с плавающей точкой, если разряд в MSR указывает, что процессор не может выполнять таких команд. Архитектура PowerPC позволяет отключать операции с плавающей точкой. Поддержка плавающей точки (Floating-Point Assist) — это прерывание используется для программной поддержки относительно редко используемых и сложных операций с плавающей точкой. Трассировка (Trace) — прерывание, генерируемое после успешного выполнения каждой трассируемой команды. Возможность пошаговой трассировки всех команд или переходов включается установкой разрядов в MSR. Системный вызов (System Call) — прерывания этого типа достигаются исполнением соответствующей команды PowerPC. Подробней об этом — в следующем разделе. Системный вызов по вектору (System Call Vectored) — тип прерывания, похожий на системный вызов. Эта команда, которая также описана в следующем разделе, аналогична команде системного вызова, но может передавать управление любой из 128 процедур. Для обработки прерываний в SLIC предусмотрены специальные процедуры. Когда аппаратура обнаруживает прерывание, управление передается одному из обработчиков исключений первого уровня FLEH (First Level Exception Handlers). То, каким образом осуществляется аппаратная передача управления, будет рассмотрено далее. Если одна из процедур FLEH обработала исключение (в основном именно так и происходит), то управление возвращается к нормальной обработке команд. Если исключение вызвано командой и не было обработано, то FLEH передает управление обработчику исключений второго уровня SLEH (Second Level Exception Handler). SLEH обрабатывает менее частые исключения, такие как исключение блокировки системного объекта. Он также отвечает за выделение исключений, которые не могут быть обработаны SLIC. Если необработанное исключение возникло, когда система исполняла команду, транслированную MI, то SLEH передает управление генератору исключений MI. Если же необработанное исключение произошло при исполнении команды SLIC, то SLEH передает управление обработчику исключений третьего уровня TLEH (Third Level Exception Handler). TLEH получает управление от SLEH, от обработчика машинных ошибок (если таковая произошла при выполнении процедуры SLIC), или от любой другой процедуры SLIC, обнаружившей исключение. Сначала TLEH вызывает обработчики исключений компонентов CSEH (Component Specific Exception Handlers), которые были установлены различными компонентами SLIC. CSEH используются для освобождения ресурсов, занятых выполнением некоторой операции, или для очистки частичных результатов неудавшейся операции, или исполнения кода, позволяющего продолжать работу при ошибке. CSEH, которые должны выполняться для данной задачи, определяются блоками CSEH, присоединенными к TDE задачи. Каждый блок CSEH содержит адрес процедуры CSEH, указатель стека и данные, необходимые этой процедуре. После выполнения всех CSEH задачи управление возвращается обратно TLEH. Затем TLEH определяет, как быть с данным исключением. Если исключение произошло в задаче SLIC, которая не является частью какого-либо процесса MI, то задача уничтожается. Если же исключение произошло в задаче, выполняющейся как часть процесса MI, то управление передается генератору исключений MI. Генератор исключений MI подготавливает данные для сообщения процессу, выполняет некоторые операции очистки и отправляет сообщение в пространство очередей соответствующего процесса. Аппаратное переключение контекста
Так как только что описанным процедурам обработки исключений может потребоваться доступ к привилегированным командам PowerPC, механизм прерываний должен иметь возможность переключать состояние процессора при передаче управления одной из таких процедур. Обычно говорят, что в этом случае происходит переключение контекста процессора. Контекст — это состояние процессора относительно привилегий, перемещения, защиты памяти, 64-разрядного режима и т. д. В дополнение к простому переключению, механизм прерываний должен выполнять синхронизацию контекста. Синхронизация означает, что аппаратура процессора обязана гарантировать завершение выполнения всех команд, запущенных до прерывания, в том же контексте, в котором они были запущены. Команды, следующие после этой операции, должны выбираться и исполняться в новом контексте. В главе 8 мы рассматривали регистр состояния машины (MSR) и значение некоторых его битов. Архитектура PowerPC определяет для MSR и некоторые другие биты, описанные в предыдущем разделе. Оставшиеся биты рассматриваться не будут, так как не относятся к обсуждаемой теме. Здесь лишь важно понимать, что значения всех битов MSR определяют контекст процессора. Значения битов могут измениться при прерывании процессора. Если при вызове процедуры SLIC необходимо изменить контекст процессора, то может быть использована команда «Системный вызов» («sc»). Эта команда в транслированных программах MI позволяет обратиться за обслуживанием к компонентам ОС в SLIC. Как мы только что упоминали, при исполнении команды «sc» процессор генерирует прерывание системного вызова. Читатели, знакомые с System/370, могут заметить, что этим команда «sc» в PowerPC очень похожа на команду «Вызов супервизора» («SVC») в архитектуре System/370. Архитектура PowerPC ведет свою родословную от разработанного в середине 70-х миникомпьютера 801, архитектура которого создавалась под большим влиянием мэйнфреймов System/370. В некотором роде и MSR — аналог «Слова состояния программы» («PSW») System/370. При возникновении прерывания аппаратура процессора PowerPC сначала выполняет синхронизацию контекста, чтобы гарантировать, что обработка прерывания не начнется, пока не будет определено, какие прерывания вызовут выполняющиеся в данный момент команды. Обратите внимание: у каждого прерывания есть приоритет. Так что если обработки ожидают несколько прерываний, то первым будет выбрано прерывание с наивысшим приоритетом. Затем эффективный адрес команды, исполнявшейся при возникновении прерывания, сохраняется в специальном 64-раз рядном регистре процессора, который называется «Регистр сохранения-восстановления состояния машины 0» или SSR 0 (Machine Status Save/Restore Register 0). Если прерывание было вызвано командой «sc», то в SSR 0 будет помещен адрес команды, следующей за «sc». Далее некоторые биты текущего MSR сохраняются в другом 64-разрядном регистре, который называется SSR 1. Наконец, остальные разряды SSR 1 заполняются информацией, специфичной для типа данного прерывания. После сохранения текущего состояния машины, аппаратура прерываний изменяет некоторые биты MSR, причем для каждого типа прерываний — свои. В частности, биты перемещения (MSRIR и MSRDR) всегда отключаются, так что процедуры — обработчики прерываний используют реальные адреса и не могут вызвать страничных ошибок. После изменения битов MSR аппаратура прерываний устанавливает адрес следующей выбираемой команды по определенному смещению относительно некоторого базового адреса. Архитектурой PowerPC определены конкретные смещения для каждого типа прерываний. Еще один бит MSR, называемый префиксом прерывания, выбирает один из двух базовых адресов. В результате только что описанной аппаратной обработки прерывания управление передается первой команде одного из обработчиков прерываний SLIC. Перед этим происходит переключение контекста процессора, так что процедура может, например, выполнять привилегированные команды. В конце процедуры обработки прерываний выполняется еще одна специальная команда PowerPC — «Возврат из прерывания» или «rfi» («Return From Interrupt))). По этой команде происходит восстановление процессора в состояние, в котором он находился до прерывания. Сначала часть битов SSR 1 помещается в соответствующие биты MSR. Затем, под управлением нового значения MSR, выбирается следующая команда по адресу из SSR 0. Если на момент возникновения только что обработанного прерывания имелись и другие ожидающие исключения, то перед выполнением первой команды в контексте, установленном командой «rti», генерируется прерывание, связанное с ожидающим исключением наивысшего приоритета. Две только что описанные команды PowerPC: «sc» и «rti», — позволяют процессору вызывать, если надо, обработчик прерывания и возвращаться к нормальной деятельности, когда прерывание обработано. В AS/400 мы хотели иметь аналогичный механизм, позволяющий одной процедуре SLIC вызывать другую. Например, планировалось обеспечить высокую эффективность вызова SLEH из FLEH. С этой целью в архитектуре PowerPC появились две новые команды: «системный вызов по вектору» или «scv» («System Call Vectored») и «возврат из системного вызова по вектору» или «rfscv» («Return From System Call Vectored»). Команда «scv» похожа на команду «sc», но есть и несколько важных отличий. Так, вместо передачи управление только по одному адресу, команда «scv» задает один из 128 адресов, по каждому из которых располагается отдельная процедура SLIC. Таким образом, с помощью команды «scv» можно эффективно передавать управление между процедурами SLIC. Другая отличительная черта «scv» в том, что эта команда не изменяет значения битов MSR. Это означает, например, что вызванная процедура может использовать виртуальные адреса. При использовании виртуальной адресации процедуры SLIC можно писать так, что будет возможна откачка их страниц на диск. Кроме того, команда «scv» не использует регистры SSR 0 и SSR 1 для сохранения состояния машины. Вместо этого, она задействует два процессорных регистра общего назначения. Команда «rfscv», как это и следует из ее названия, выполняет возврат после «scv». Задания и управление ими OS/400 Прочитав предшествующие разделы, Вы увидели, как развита современная структура процессов. Наряду с огромными возможностями, она отличается и огромной сложностью в управлении, которое едва ли под силу рядовому пользователю. В соответствии с философией технологической независимости и интегрированности, AS/400 берет и эту обязанность на себя посредством компонента управления заданиями OS/400. Пользователь имеет дело с определением задания, которое точнее соответствует прикладной программе. Все остальное делает OS/400 и нижележащие компоненты. Построение всей структуры заданий поверх модели процессов имеет один недостаток: намного меньшую гибкость, чем при настройке характеристик процесса в соответствии с характеристиками конкретного приложения. Подобная настройка позволяет повысить производительность приложения, которому не нужны все возможности, предоставляемые структурой задач. Фундаментальным строительным блоком многих новых ОС становится облегченный процесс или подпроцесс, который обычно называют потоком (thread). Приложения, написанные для потоковой модели, не используют полнофункциональную структуру задач, и вследствие этого достигают большей производительности при переключении с одной программы на другую. Важно отметить, что структура задач AS/400 на аппаратном уровне — одна из наиболее эффективных. В коммерческом приложении значительная часть (до 80 — 90 процентов) обработки, выполняется ОС, а не самим приложением. Приложение запрашивает обработку у ОС, вместо того чтобы выполнять ее самостоятельно. Непосредственно выполнением такой обработки занимается, в основном, SLIC, где структура задач очень эффективна. Давайте рассмотрим, как в AS/400 поддерживаются потоки, и как это позволяет переносить приложения, написанные для других ОС. Концепции управления заданиями Управление заданиями, переданными пользователем AS/400, выполняется компонентом управления заданиями OS/400. Задание — это единица работы, переданной на выполнение. Как Вы помните, управление заданиями различает несколько типов заданий, включая традиционные интерактивные и пакетные. В предшествующих разделах обсуждался процесс, как единица работы, переданной управлением заданиями нижележащим компонентам. Объекту-процессу MI нет аналогов в OS/400. Задание — это не объект OS/400. Не являются таковыми и маршрутизация или подсистемы, которые мы скоро будем рассматривать. Управление заданиями имеет дело непосредственно с процессами. Задание может выполняться в рамках одного или нескольких процессов, запуск которых осуществляется одним или несколькими управляющими процессами. Каждый новый запуск процесса при выполнении задания называется шагом маршрутизации (routingstep).
Рисунок 9.6. Концепции управления работой Управление заданиями рассматривает систему как иерархию доменов, показанную на рисунке 9.6. Шаг — самый низкий уровень этой иерархии. Следующий уровень — задание, которое обрабатывается одним или несколькими последовательными шагами. Задания находятся в подсистемах, каждая из которых содержит задания сходного типа, например, все интерактивные задания. Как мы скоро увидим, подсистемы управляют некоторыми системными ресурсами. Наконец, самый верхний уровень иерархии — собственно система, где повсеместно используются некоторые системные параметры и сетевые атрибуты. Пример — имя компьютера в вычислительной сети. Подсистемы Подсистема AS/400 — это одна из предопределенных операционных сред. Все задания в подсистеме должны иметь одинаковый тип (например, пакетные) и совместно использовать определенные системные ресурсы. Так как конфигурация подсистем и то, какие именно задания выполняются в данной подсистеме, могут быть разными на разных AS/400, то нет гарантии, что все задания в подсистеме однотипны. С каждой подсистемой связан объект OS/400 под названием описание подсистемы. Описание подсистемы содержит общую информацию о выделенных подсистеме ресурсах и указывает на другие объекты OS/400: описание задания, классы и программы, — предоставляющие дополнительную информацию об этой подсистеме. Описание задания — это объект OS/400, задающий атрибуты и ресурсы, связанные с заданием. Он определяет: список библиотек (по умолчанию); очередь заданий; данные маршрутизации; принтер (по умолчанию); приоритет планировщика вывода; профиль пользователя. Класс представляет собой объект OS/400, содержащий параметры, которые задают среду выполнения. Некоторые из них относятся к выделенным заданию ресурсам процессора. Например, может быть ограничено число процессов класса, выполняющихся одновременно. Это позволяет управлять объемом взаимного влияния процессов, конкурирующих за один и тот же системный ресурс. Данный предел, обычно называемый уровнем активности, связан с пулом памяти. Пул памяти, (не путать с пулом вспомогательной памяти!) — это средство резервирования для подсистемы некоторого объема основной (оперативной) памяти. В основной памяти может быть размещено до 16 пулов памяти, один из которых всегда зарезервирован машиной. Пул памяти — это часть памяти, куда осуществляется динамическая подкачка страниц процессов, связанных с этим пулом. Например, один пул памяти может быть выделен для всех интерактивных заданий, а другой — для всех пакетных. Такой подход позволяет гарантировать, что пакетное задание не отберет себе страничный фрейм у интерактивного задания, и таким образом не повлияет на время ожидания ответа пользователем. Пакетные задания могут отбирать только страничные фреймы у других пакетных задач из пакетного пула памяти. Пулы памяти определяются в описании подсистемы. Размеры, число и уровни активности пулов памяти управляются пользователем системы. Таким образом, система может быть настроена так, чтобы обеспечить максимальную производительность именно для данного пользователя. Подобная настройка в AS/400 при помощи различных средств выполняется вручную или автоматически при изменении характера рабочей нагрузки. Старая и новая структуры задания С появлением модели процессов ILE, описанной ранее, изменилась и структура задания в AS/400. Как именно — можно понять, сравнив ресурсы приложений, доступные в старой и новой структурах заданий, а также особенности их использования. Как правило, ресурсы приложений для задания включают в себя разделяемые файлы, управление транзакциями и память.
Процессы, задачи, задания, группы активизации и потоки Как уже упоминалось, первоначально в AS/400 было определено три уровня работы. Самый низкий уровень, под MI, — задача. Процесс «живет» на уровне MI и построен на структуре задач SLIC. Поверх модели процессов MI OS/400 в качестве единицы работы поддерживает задание. Большинство других ОС работают непосредственно с процессами. Но не OS/400. В этом отношении задание в ней — аналог процесса в других ОС. Полнофункциональное задание обеспечивает лучшие возможности разделения ресурсов и защиты, чем процессы в других ОС; однако, для создания такого задания нужно больше времени. Задание AS/400 можно называть «полновесным». Приложения, написанные специально для AS/400, обычно соответствуют структуре полнофункционального задания, то есть, исполняются внутри одного задания. Динамическое создание множества заданий для одного приложения не рекомендуется, из-за больших накладных расходов. Конечно, для некоторых других ОС приложения пишутся не так. Например, Unix и Windows NT определяют структуру, в которой процессы могут быстро создаваться, существовать и затем разрушаться. Приложения, написанные для таких ОС, часто используют множество процессов. Для достижения достаточной производительности приложениям такого типа нужен очень «легковесный» процесс. Данная тенденция привела к новому пониманию процесса. Например, в модели POSIX процессы разделены на два отдельных компонента. Первый содержит все ресурсы для группы взаимодействующих единиц. Эти ресурсы включают в себя виртуальную память, коммуникационные порты и файлы, выделенные процессу. Некоторые ОС даже называют эту часть процесса задачей. Вторая часть процесса — активная среда выполнения, обычно называемая потоком. В процессе может исполняться один или несколько параллельных потоков. Исходное определение процесса было ограничено только одной исполняющейся единицей. Новое определение допускает несколько единиц исполнения — потоков. Поток — это подпроцесс, который имеет доступ к некоторым собственным ресурсам, а также к разделяемым ресурсам процесса. Таким образом, в многопоточном процессе может исполняться несколько потоков, совместно использующих системные ресурсы. Достоинство потоков в том, что они позволяют разным частям одного приложения исполняться параллельно. Особенно важны потоки в распределенной среде, они обязательны для стандарта, известного как DCE (Distributed Computing Environment). DCE использует модель процессов POSIX. Поскольку мы хотели реализовать в AS/400 интерфейсы DCE и POSIX, нам нужно было найти некоторый способ поддержки потоков POSIX. Мы рассмотрели две модели. Первая — встроенные потоки, где в процессе принимают участие множество TDE, для каждой группы активизации — собственный. Таким образом, группа активизации становится отдельной единицей диспетчирования, своего рода аналогом потока. Данная модель достаточно точно соответствует общепринятой модели потоков. К сожалению, она также требовала внесения в OS/400 множества изменений, больше, чем позволяло время, отведенное на проект V3R1. Поэтому для начала нам пришлось выбрать вторую, несколько менее удачную модель. Вторая модель потоков основывалась на концепции разделяемой группы активизации. Несколько заданий OS/400 могут разделять одну группу активизации. Таким образом, поток — задание OS/400, использующее разделяемую группу активизации. Процесс POSIX может быть представлен как совокупность всех заданий OS/400, совместно использующих группу активизации. Все потоки процесса POSIX совместно используют общие статическую память и кучу, при этом у каждого из них своя автоматическая память (стек). Такое использование задания OS/400 в качестве потока, успешно работает, но имеет один существенный недостаток: для создания полнофункционального задания требуется больше времени, по сравнению с другими системами, где применяются «легковесные» потоки. Для повышения производительности AS/400 мы предусмотрели пул заранее созданных заданий. Когда нужно быстро создать поток, используется одно из заданий пула. При разрушении потока задание возвращается в пул. Данная модель потоков была представлена как часть CPA (Common Programming) API в V3R1. Начальная цель была достигнута, но мы знали, что это паллиатив. Хотелось перенести на AS/400 несколько других приложений, например, Lotus Domino. Мы рассмотрим Domino в его связи с AS/400 в главе 11, сейчас же нам следует признать, что Domino написан для потоковой модели. Так, подгоняемые мечтой о нормальной работе Domino на AS/400, мы начали проектирование встроенных потоков для версии V4 OS/400. На рисунке 9.7 показано соотношение двух потоковых моделей системы и средств поддержки приложений (application enabler). Последние включают в себя библиотеки времени исполнения для языков, типа С, С+ + и Java, интегрированную файловую систему и библиотеки классов объектов. В главе 11 мы рассмотрим Java и его объектную модель, а также модели IBM SOM (System Object Model) и DSOM (Distributed System Object Model).
Рисунок 9.7. Средства поддержки приложений для потоков Мы полагаем, что с течением времени все больше и больше приложений будет создаваться для потоковой модели. Поддержка потоков часто позволяет приложениям, написанным для какой-либо другой ОС, эффективно работать на AS/400. Выводы В разных ОС процессы реализованы по-разному. Каждая система определяет мощность процесса, его структуру, а также то, как он должен быть защищен. Модель процессов AS/400 доказала свою высокую эффективность и способность поддержки важнейших приложений. Современнейшая структура задач, на основе которой работают все остальные функции системы, позволяет моделям процессов и заданий эволюционировать для нужд будущих сред приложений. В следующей главе мы рассмотрим подсистему ввода-вывода и направления ее развития для поддержки будущих приложений AS/400. Структура задач играет важную роль в системе ввода-вывода. Это верно и теперь, и в будущем. Примечания:7 На самом деле все гораздо хуже — некоторые программы явно рассчитывают на 16-разрядную адресацию. Например в них сильно изменяются условия возникновения переполнения при выполнении арифметических операций в регистрах и т. д. Очевидно, что такого рода зависимости не проявляются сразу после перехода с 16-ти на 32-х разрядные процессоры (регистры) и в результате появляются «плавающие» ошибки, которые очень трудно обнаружить.—Прим. консультанта. 75 Ни одноуровневая память, ни независимость от технологии запатентованы не были. — Прим. консультанта. |
|
||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | Контакты | Нашёл ошибку | Прислать материал | Добавить в избранное |
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||